[TUTORIAL] HOW TO PAUSE AN AWS ELASTIC BEANSTALK ENVIRONMENT USING THE DASHBOARD
So you have set up a test elastic beanstalk environment because you don’t want to put at risk your production…
So you have set up a test elastic beanstalk environment because you don’t want to put at risk your production…
Save the following script in a file called speed_test #!/bin/bash # Requirements # sudo apt-get install lftp iperf lftp -e…
First of all, create a snapshot of your EBS volume. Then out of that snapshot you will be able to…
So you’ve created an Elastic Beanstalk environment, you have a play framework distribution which you’ve created using play dist (either…
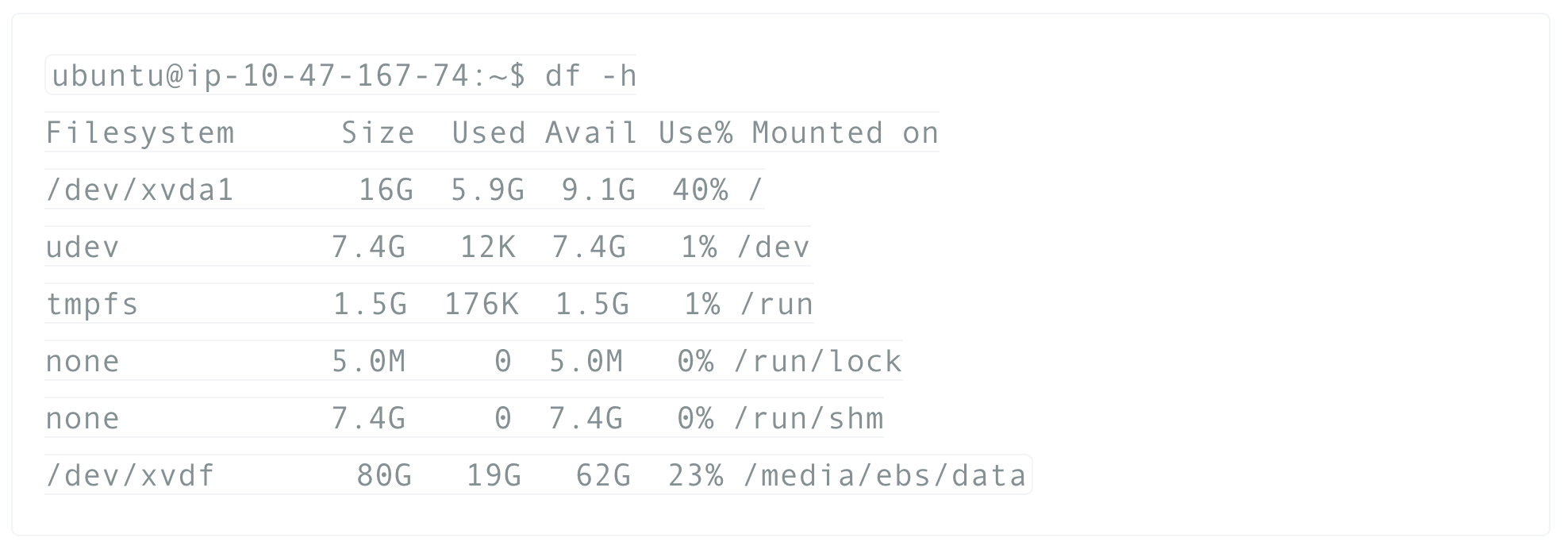
So the /etc/fstab file on your root volume looked like this LABEL=cloudimg-rootfs / ext4 defaults 0 0 /dev/xvdf /mnt/backups auto…